Titanic - Machine Learning from Disaster
24 de marzo de 2025
Kaggle Titanic Challenge
Ubicación del DataSet: https://www.kaggle.com/c/titanic/data
El DataSet se utilizará para construir sus modelos de aprendizaje automático. Se proporcionará el resultado (ground truth) de cada pasajero. Su modelo se basará en “propiedades” como el sexo y la clase de los pasajeros. El conjunto de pruebas se utilizará para comprobar el rendimiento del modelo con datos no observados. Para el conjunto de prueba, no se proporcionará el ground truth para cada pasajero. Se predecirán los resultados. Para cada pasajero del conjunto de prueba. Se utilizará el modelo que se ha entrenado para predecir si sobrevivieron o no al hundimiento del Titanic.
Propiedades destacables
-
pclass: Un indicador indirecto del estatus socioeconómico (SES)
-
- Alto
-
- Medio
-
- Bajo
-
-
age: La edad es fraccionaria si es inferior a 1. Si la edad es estimada, es en forma de xx.5.
-
sibsp: El conjunto de datos define las relaciones familiares de esta manera:
- sibling = hermano, hermana, hermanastro, hermanastra.
- spouse = marido, mujer (se ignoran las amantes y los prometidos).
-
parch: El conjunto de datos define las relaciones familiares de la siguiente manera:
- parent = madre, padre.
- child = hija, hijo, hijastra, hijastro.
Algunos niños viajaron sólo con una niñera, por lo que parch es 0 para ellos.
Comienzo de la resolución
Se creará un nuevo “Notebook”, el entorno de trabajo proporcionado por kaggle con las bibliotecas necesarias instaladas.
Se importarán los DataSets necesarios a dicho entorno.
Librerías Importadas
En el Notebook se muestra un script en Python con varias librerías importadas por defecto:
- numpy (
np): Biblioteca para trabajar con matrices y funciones matemáticas avanzadas. - pandas (
pd): Biblioteca para manipulación y análisis de datos en DataFrames. - os: Biblioteca para manejar funciones del sistema operativo.
Se itera por cada fichero en el directorio donde se almacenan los DataSets y se muestran los archivos.
-
train.csv: Contiene los datos de entrenamiento, con la variable objetivo Survived:
- 1 = Sobrevivió
- 0 = No sobrevivió
-
test.csv: Contiene los datos de prueba, sin la variable Survived, que será el conjunto sobre el cual se harán las predicciones.

Se definirán diferentes variables con dichos archivos CSV. Se importarán las librerías necesarias para entrenar el modelo y trabajar con diferentes estructuras de datos, como DataFrames.
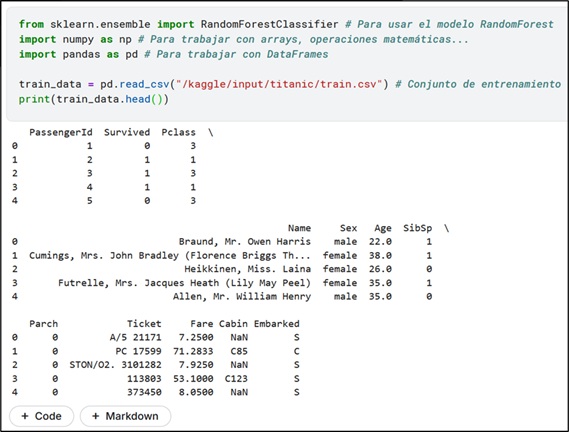
Examinado el archivo train.csv, se puede encontrar una columna con el sexo de cada pasajero.
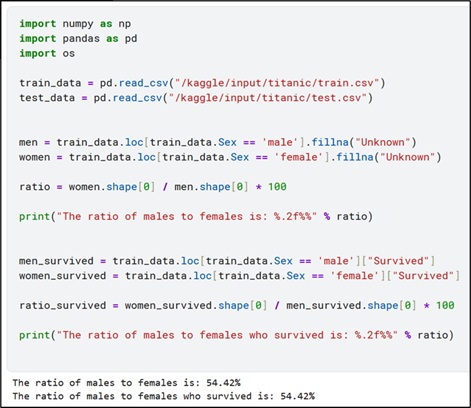
A modo de ejemplo de cómo se puede operar con estos datos, se puede tratar de obtener la proporción de pasajeros en función de este parámetro.
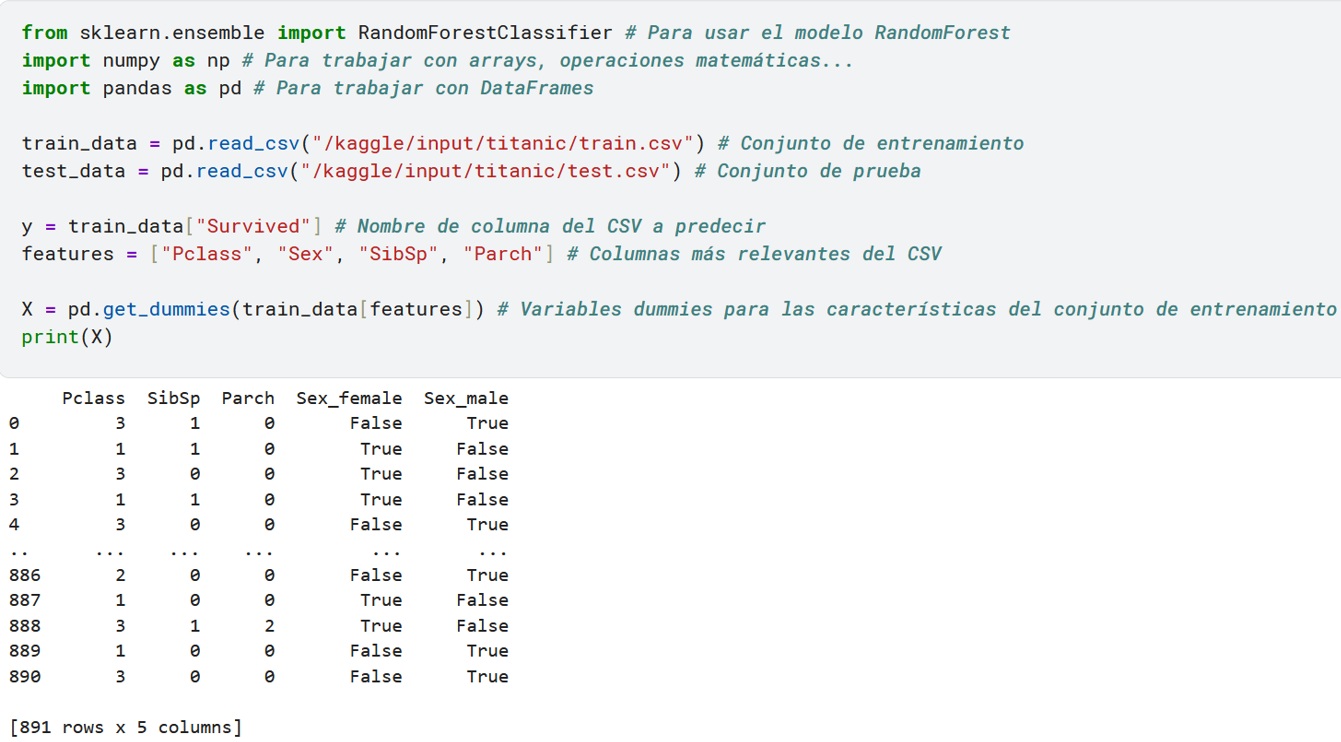
Creación del DataFrame
Un DataFrame es una estructura de datos bidimensional y etiquetada, similar a una hoja de cálculo o una tabla SQL, que organiza los datos en filas y columnas, donde cada columna puede contener datos de tipos diferentes; es ampliamente utilizado en Pandas para análisis, manipulación y visualización de datos, así como en aprendizaje automático, gracias a su flexibilidad y a la amplia gama de funciones que ofrece para trabajar con datos tabulares de manera eficiente.
Esto tendrá la siguiente forma en el ejemplo:
De la misma forma, pero para el conjunto de prueba:
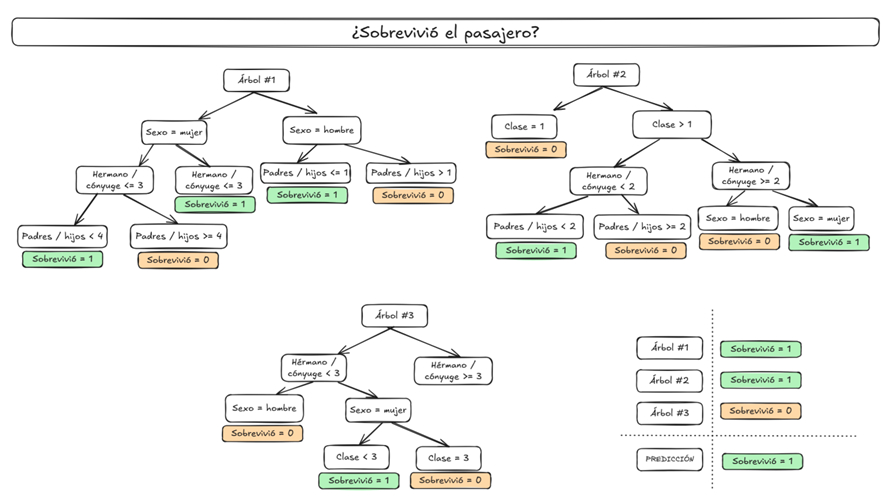
Definición del Modelo
Se utilizará un modelo basado en la aleatoriedad estadística: Random Forest. Para su configuración, se deben definir los siguientes parámetros:
-
n_estimators: Controla el número de árboles de decisión que se construirán en el bosque aleatorio (Random Forest).
- En este caso, se están creando 100 árboles de decisión.
-
max_depth: Controla la profundidad máxima de cada árbol de decisión individual en el bosque.
- En este caso, cada árbol tendrá una profundidad máxima de 5 niveles.
- La profundidad del árbol influye en la capacidad de captura de patrones:
- Un valor bajo de
max_depthpuede llevar a underfitting (modelo demasiado simple). - Un valor alto de
max_depthpuede llevar a overfitting (modelo demasiado ajustado a los datos de entrenamiento).
- Un valor bajo de
-
random_state: Controla la semilla utilizada por el generador de números aleatorios.
- Al establecer un valor fijo (1), garantizamos que los resultados del modelo sean reproducibles.
- Los algoritmos de Random Forest incluyen aleatoriedad en la selección de muestras y características para construir los árboles.
- Al fijar
random_state, se asegura que cada ejecución del código produzca el mismo modelo, siempre que los datos de entrada sean los mismos.
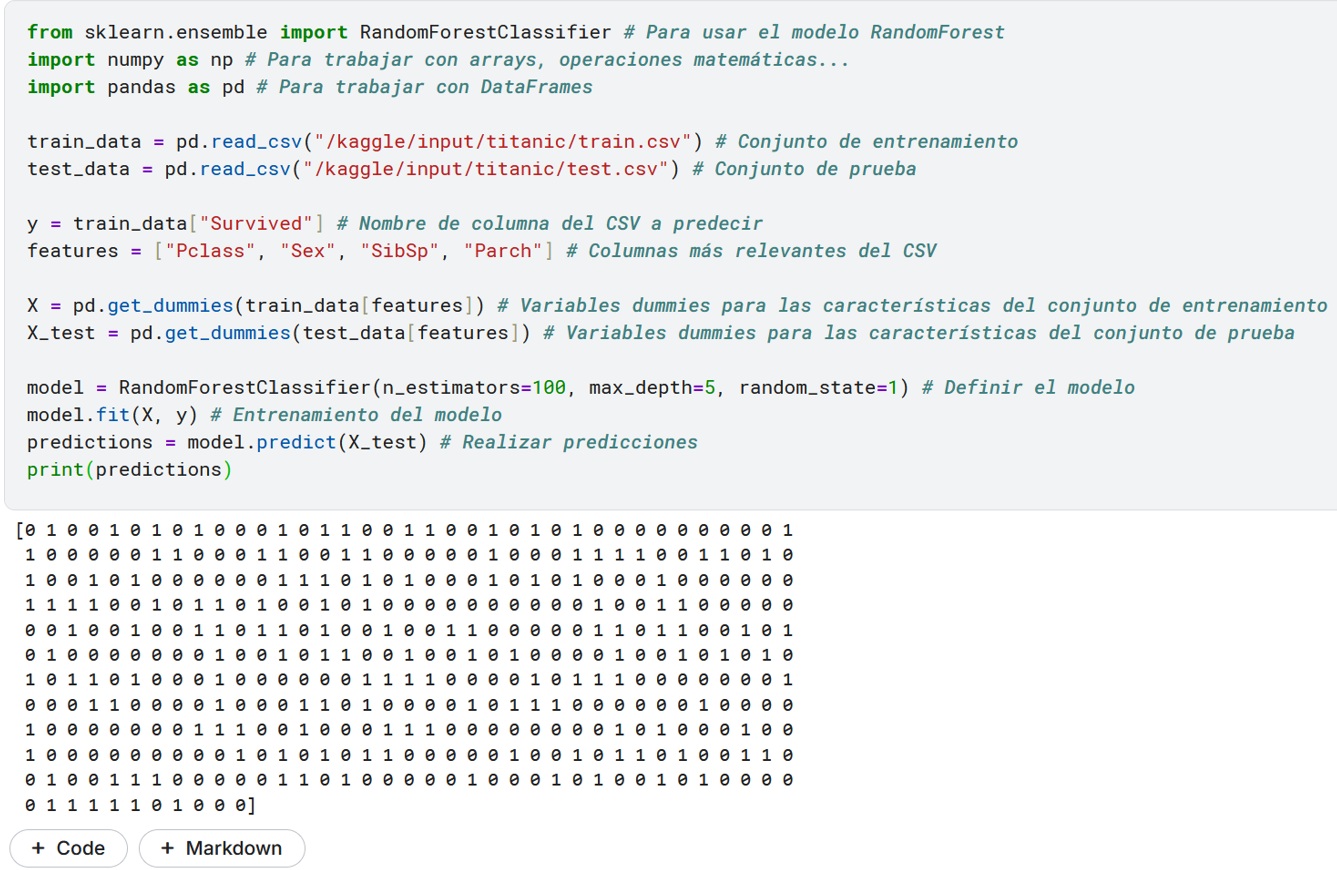
Finalmente, estas predicciones se almacenarán en un nuevo CSV.
Estará disponible para su descarga en Kaggle.
